Introduction
A proper semantic representation for encoding side information is key to the success of zero-shot learning. In this paper, we explore two alternative semantic representations especially for zero-shot human action recognition: textual descriptions of human actions and deep features extracted from still images relevant to human actions. Such side information are accessible on Web with little cost, which paves a new way in gaining side information for large-scale zero-shot human action recognition. We investigate different encoding methods to generate semantic representations for human actions from such side information. Based on our zero-shot visual recognition method, we conducted experiments on UCF101 and HMDB51 to evaluate two proposed semantic representations . The results suggest that our proposed text- and image-based semantic representations outperform traditional attributes and word vectors considerably for zero-shot human action recognition. In particular, the image-based semantic representations yield the favourable performance even though the representation is extracted from a small number of images per class.
framework
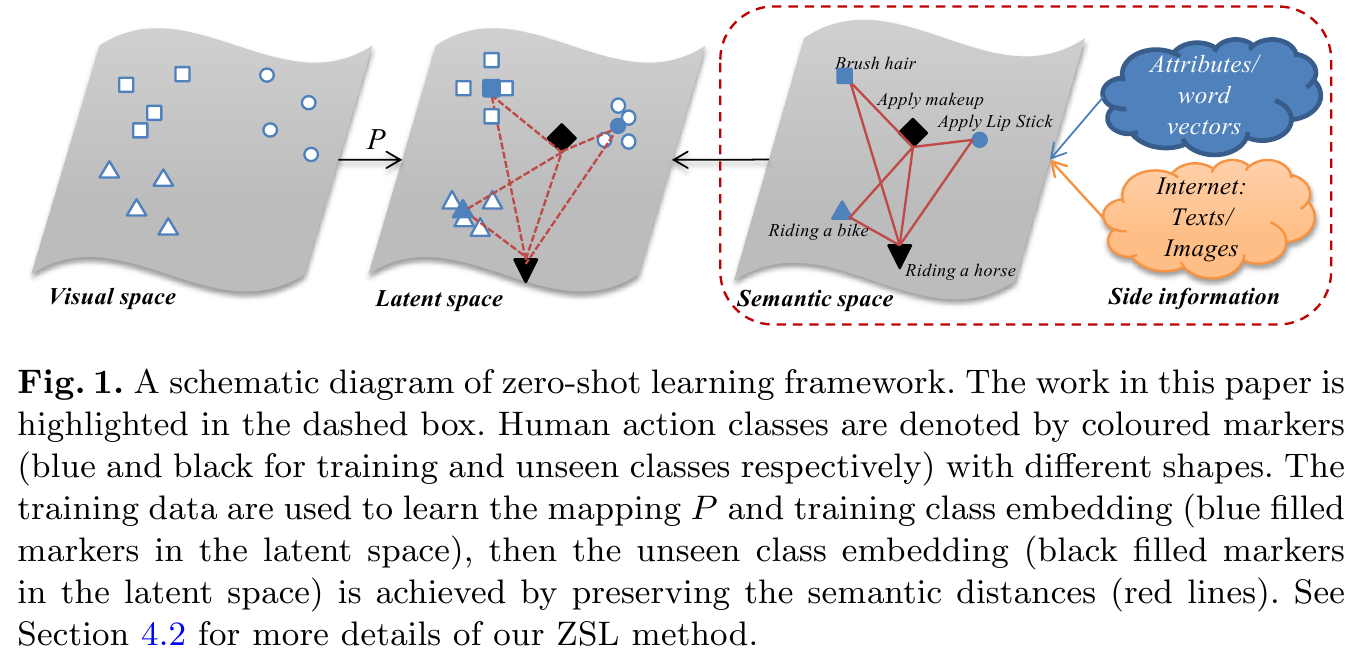
Side Information Collection

Experimental Results
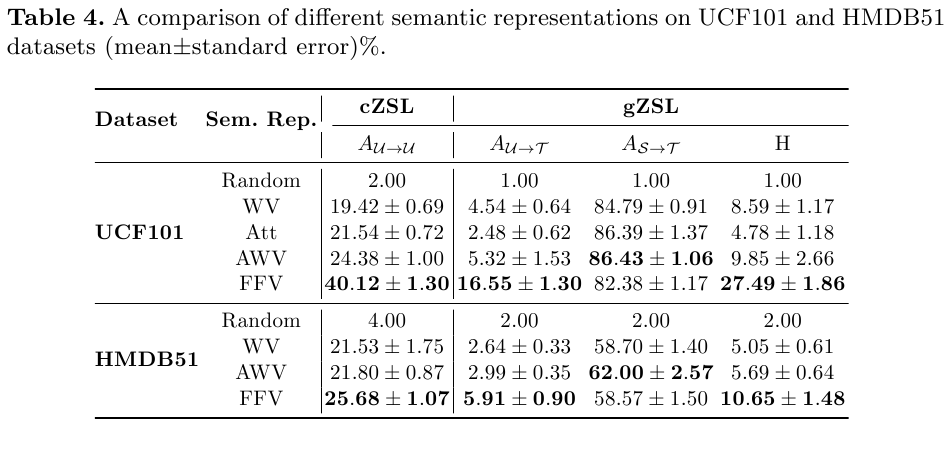
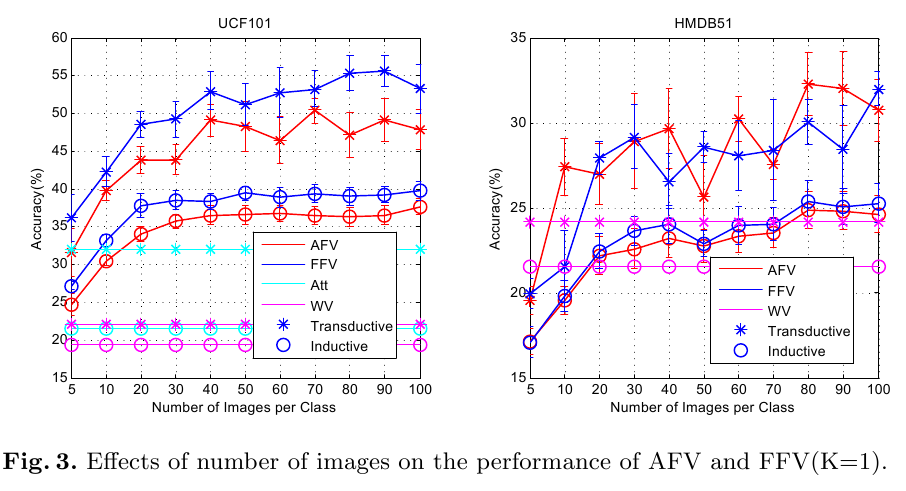
Codes and Data
If you are interested in our work, the codes and data (e.g., pre-computed visual representations, semantic representations used in our experiments) are available upon request. The details of the codes and data are described here.
Related Paper
Wang, Q. and Chen, K. (2017). Alternative Semantic Representations for Zero-Shot Human Action Recognition. Proc.ECML-PKDD 2017.