Introduction
Human action recognition refers to automatic recognizing human actions from a video clip, which is one of the most challenging tasks in computer vision. Due to the fact that annotating video data is laborious and time-consuming, most of the existing works in human action recognition are limited to a number of small scale benchmark datasets where there are a small number of video clips associated with only a few human actions and a video clip often contains only a single action. In reality, however, there often exist multiple human actions in a video stream. Such a video stream is often weakly-annotated with a set of relevant human action labels at a global level rather than assigning each label to a specific video episode corresponding to a single action, which leads to a multi-label learning problem. Furthermore, there are a great number of meaningful human actions in reality but it would be extremely difficult, if not impossible, to collect/annotate video clips regarding all of various human actions, which leads to a zero-shot learning scenario. To the best of our knowledge, there is no work that has addressed all the above issues together in human action recognition. In this paper, we formulate a real-world human action recognition task as a multi-label zero-shot learning problem and propose a framework to tackle this problem in a holistic way. Our framework holistically tackles the issue of unknown temporal boundaries between different actions for multi-label learning and exploits the side information regarding the semantic relationship between different human actions for knowledge transfer. As a result, our framework leads to a joint latent ranking embedding for multi-label zero-shot human action recognition. A novel neural architecture of two component models and an alternate learning algorithm are proposed to carry out the joint latent ranking embedding learning. Thus, multi-label zero-shot recognition is done by measuring relatedness scores of action labels to a test video clip in the joint latent visual and semantic embedding spaces. We evaluate our framework with different settings, including a novel data split scheme designed especially for evaluating multi-label zero-shot learning, on two weakly annotated multi-label human action datasets: Breakfast and Charades. The experimental results demonstrate the effectiveness of our framework in multi-label zero-shot human action recognition.
framework
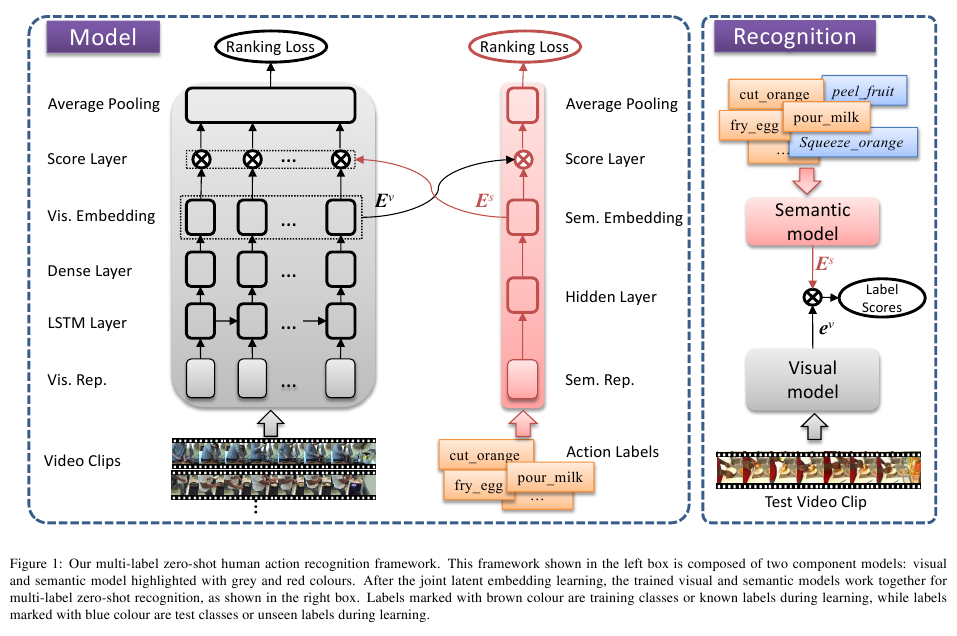
Dataset and Split
We conducted experiments on two datasets, i.e., Breakfast, Charades, via two different data split settings, instance-first and label-first splitting, that simulate zero-shot human action recognition scenarios. For details of our data split settings, see our paper and the split data subsets used in our experiments are available upon request (see below for the information).
Experimental Results
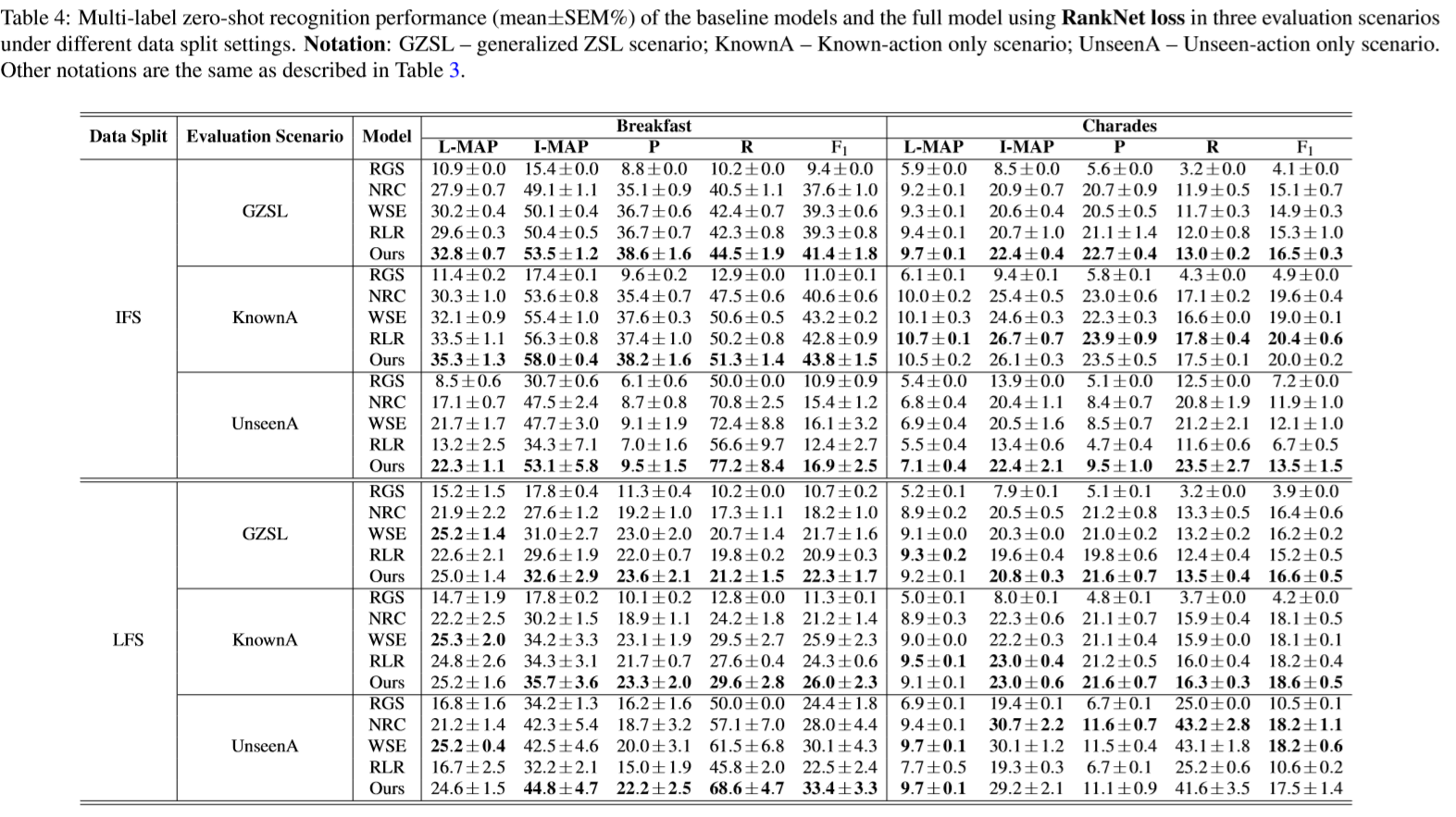
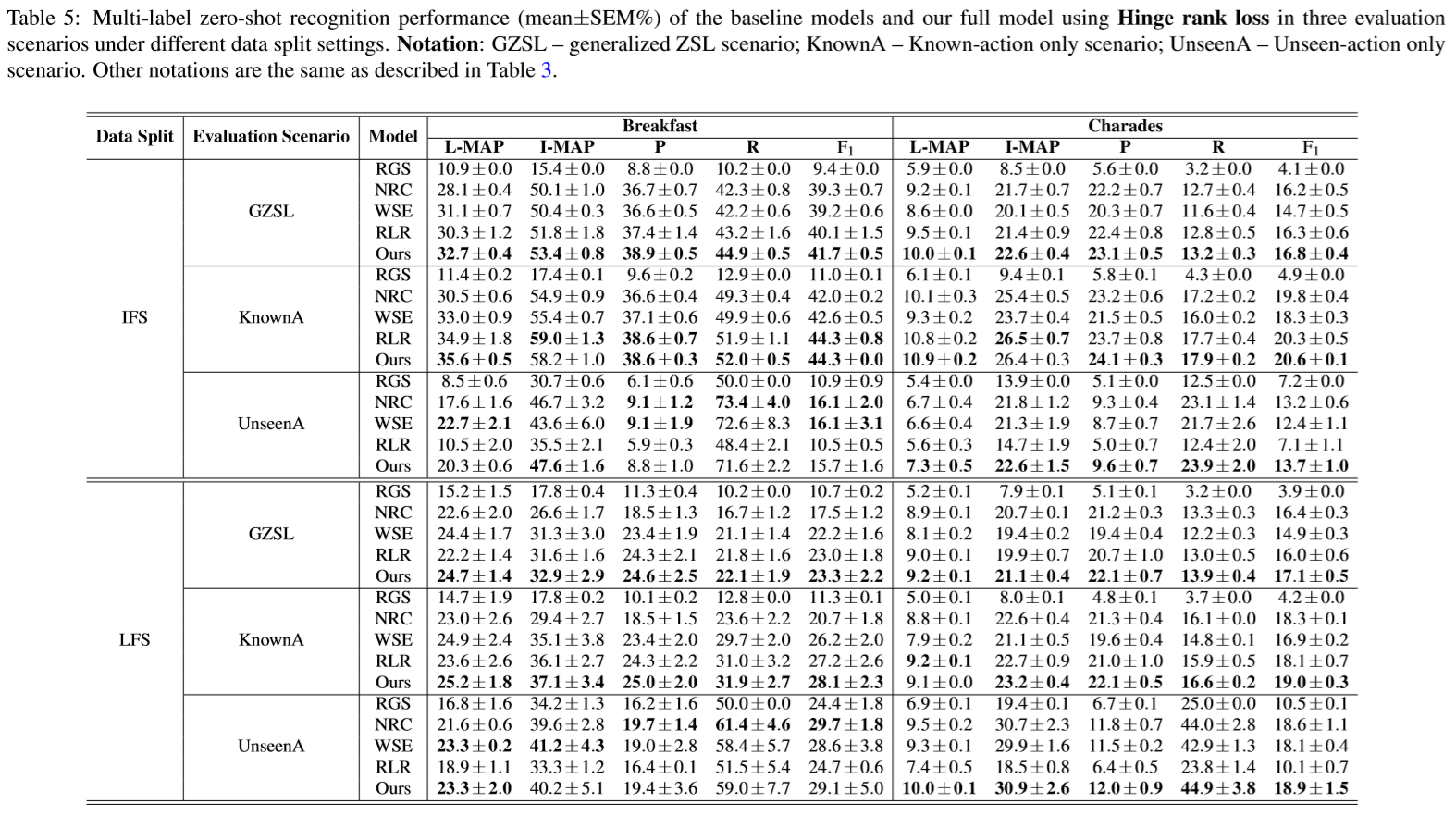
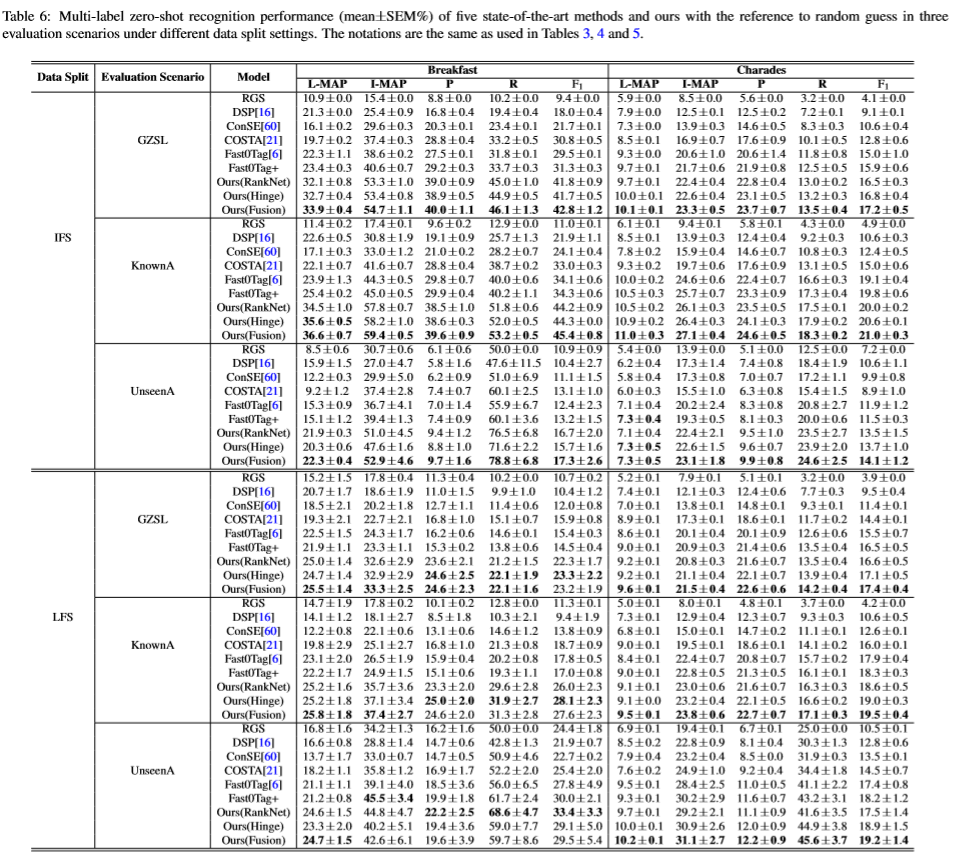
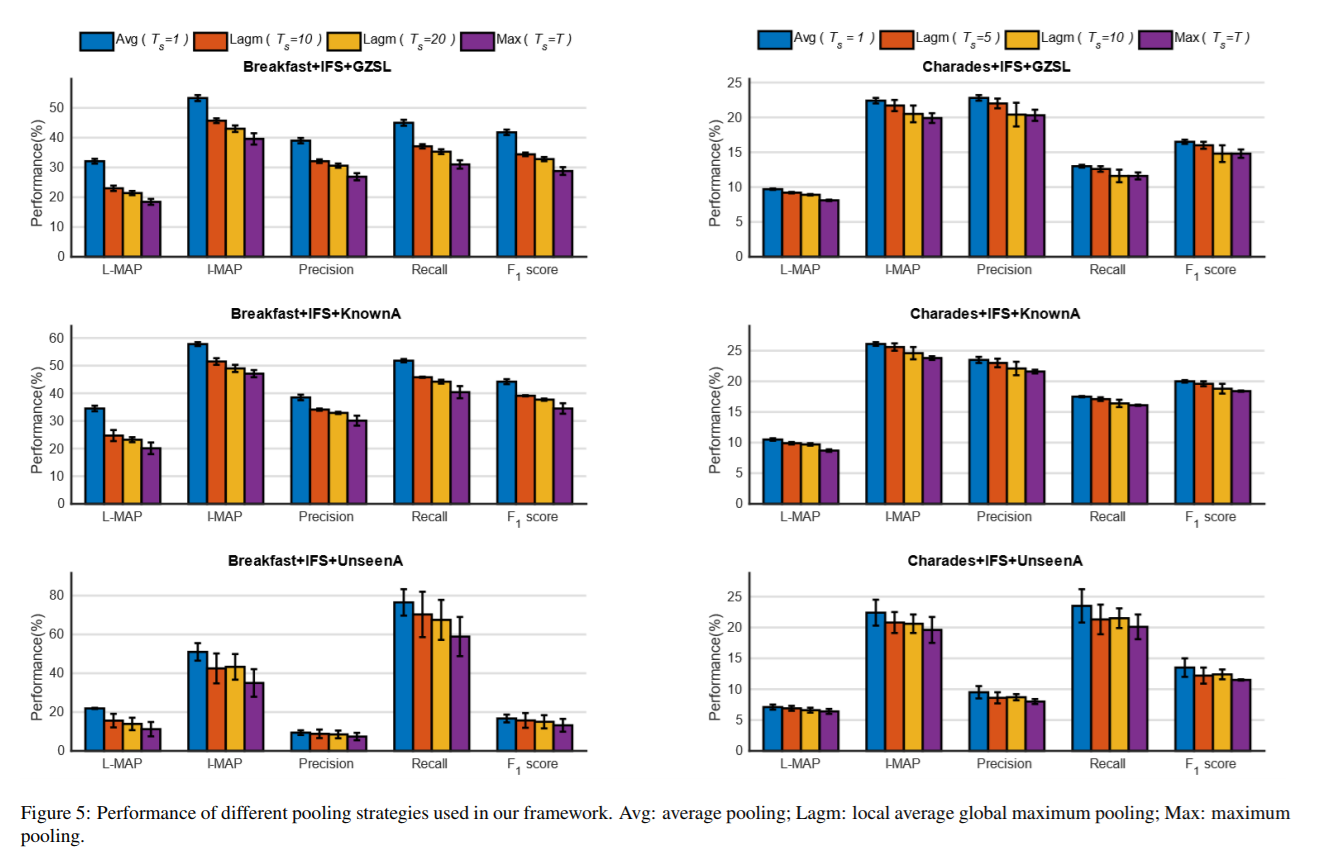
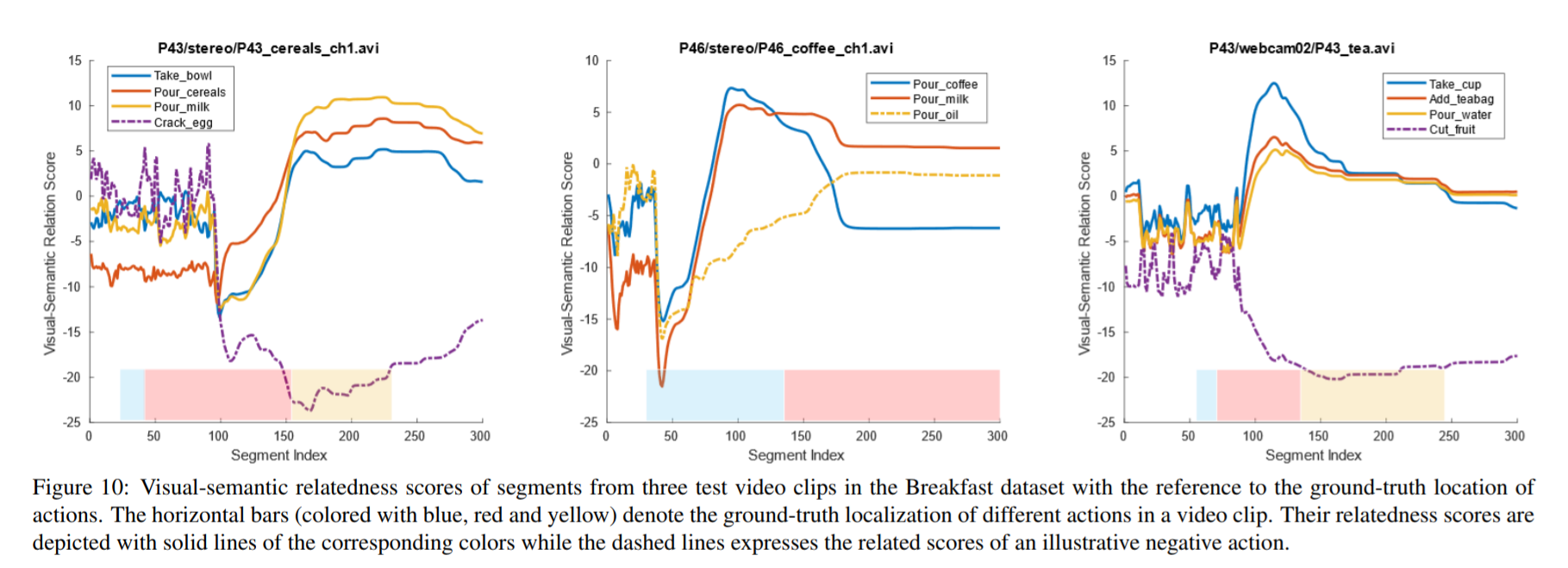
Codes and Data
If you are interested in our work, the codes and data (e.g., pre-computed visual representations, semantic representations used in our experiments) are available upon REQUEST.
You are welcome to send your comment to Qian Wang and Ke Chen.
Related Papers
Wang, Q., & Chen, K. (2020). Multi-Label Zero-Shot Human Action Recognition via Joint Latent Ranking Embedding.ĀNeural Networks 122(2): 1-23. [Article]
Wang, Q., & Chen, K. (2017). Multi-Label Zero-Shot Human Action Recognition via Joint Latent Embedding.ĀarXiv preprint arXiv:1709.05107. [Paper]