Introduction
Zero-shot learning for visual recognition, e.g., object and action recognition, has recently attracted a lot of attention. However, it still remains challenging in bridging the semantic gap between visual features and their underlying semantics and transferring knowledge to semantic categories unseen during learning. The existing zero-shot visual recongition might be divided into three categories: a direct mapping from visual features to their semantic representations, a common latent space by embedding visual features and their semantic representations to a common representational space and transferring model parameters learned from training data to those models used to deal with unseen classes.
In this project, we explore zero-shot visual recongition with a perspective of briging semantic gap explicitly. Unlike the existing zero-shot visual recongition, we propose a stagewise bidirectional latent embedding framework of two subsequent learning stages for zero-shot visual recognition. In the bottom-up stage, a latent embedding space is first created by exploring the topological and labeling information underlying training data of known classes via supervised locality preserving projection and the latent representations of training data are used to form landmarks that guide embedding semantics underlying unseen classes onto this latent space. In the top-down stage, semantic representations for unseen classes are then projected to the latent embedding space to preserve the semantic relatedness via the semi-supervised Sammon mapping with landmarks. As a result, the resultant latent embedding space allows for predicting the label of a test instance with a simple nearest neighbor rule .
To evaluate the effectiveness of the proposed framework, we have conducted experiments on four benchmark datasets in object and action recognition, i.e., AwA, CUB-200-2011, UCF101 and HMDB51. The experimental results under comparative studies demonstrate that our proposed approach yields the state-of-the-art performance. In particular, our proposed framework yields the following peformance measured by the averaging per-class accuracy: 79.2% (inductive setting) and 95.1% (transductive setting) on AwA, 50.0% (inductive setting) and 63.2% (transductive setting) on CUB-200-2011, 22.8%(43.5%) for the 51/50(81/20) split (inductive setting) and 32.0%(58.1%) for the 51/50(81/20) split (transductive setting) on UCF101 and 20.4% (inductive setting) and 20.7% (transductive setting) on HMDB51.
framework
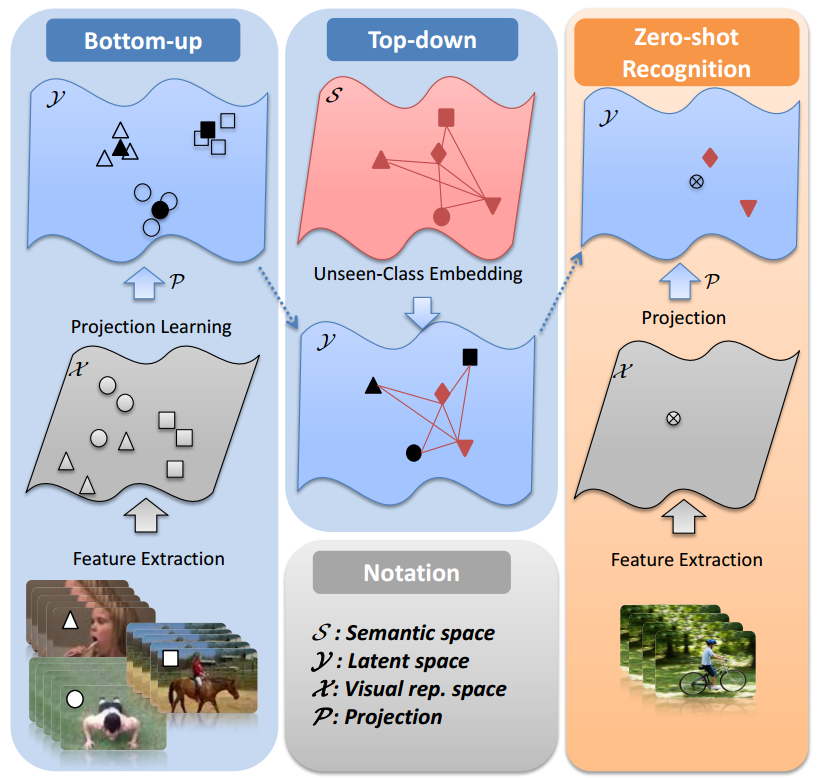

Data and Splits
We conducted experiments on four datasets, i.e., AwA, CUB-200-2011, UCF101 and HMDB51. We use a standard 40/10 split for AwA, a standard 100/50/50 split (available from here) for CUB-200-2011, 30 randomly generated 51/50 and 81/20 splits for UCF101, 30 randomly generated 26/25 splits for HMDB51. The data splits used in our experiments can be downloaded here (.mat files), among which the data splits for UCF101 (51/50) and HMDB51 are from Xun Xu's website, and UCF101 (80/21) splits are generated randomly by ourselves.
Additional Experimental Results
As there are 30 training/test splits for UCF101 (51/50), UCF101 (81/20) and HMDB51, respectively, the classwise cross-validation has to be conducted on each split independently in different scenarios that different visual and semantic representations are used. We report the detailed experimental results on 30 splits of each dataset in different scenarios HERE.
Codes and Data
If you are interested in our work, the souce codes and data (i.e., extracted visual representations and semantic representations used in our experiments) are available here. The details of the codes and data are described here.
You are welcome to send your comment to Qian Wang and Ke Chen.
Related paper
Wang, Q. and Chen, K. (2017): Zero-shot visual recognition via bidirectional latent embedding. International Journal of Computer Vision 124(3): 356--383.