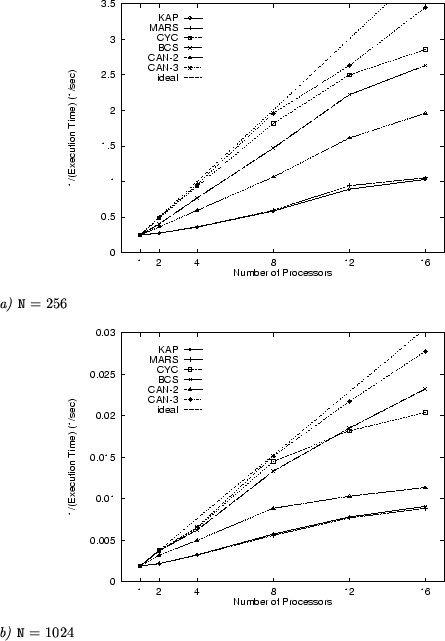
The second benchmark, banded symmetric rank-![]() update
(SYR2K), contains non-affine
bounds; the version we use is shown below.
update
(SYR2K), contains non-affine
bounds; the version we use is shown below.
DOALL I=1,MIN(N,2*BB-1)
DO J=MAX(1-BB,1-N),MIN(BB-I,N-I)
DO K=MAX(1,I+J),MIN(N+J,N)
C(-I-J+K+1,I)=C(-I-J+K+1,I)+A(K,-I-J+BB+1)*B(K,-J+BB)
& +A(K,-J+BB)*B(K,-I-J+BB+1)
ENDDO
ENDDO
ENDDO
Clearly, the loop nest is not canonical (see
Definition 1). However, converting the MIN and MAX
functions to IF statements, and removing the
latter by index set splitting (see Section
3.2), the code can be
transformed into four consecutive canonical loop nests assuming that
N ![]() 2*BB-1 [15]; this version
is denoted CAN-3t. For comparison, two additional mapping
schemes are also implemented; they are based on direct application
of the partitioning schemes described by (7) for
2*BB-1 [15]; this version
is denoted CAN-3t. For comparison, two additional mapping
schemes are also implemented; they are based on direct application
of the partitioning schemes described by (7) for ![]() and
and ![]() to the original loop nest, regardless of the fact that
the latter is not canonical. These two versions are henceforth
referred to as CAN-2 and CAN-3, respectively. No version
based on balanced chunk scheduling is implemented since loop nests
having bounds containing MIN and MAX functions do not
conform to its requirements.
to the original loop nest, regardless of the fact that
the latter is not canonical. These two versions are henceforth
referred to as CAN-2 and CAN-3, respectively. No version
based on balanced chunk scheduling is implemented since loop nests
having bounds containing MIN and MAX functions do not
conform to its requirements.
The load imbalance, ![]() , computed in terms of the work associated
with the assignment statement of the loop body, and the corresponding
relative load imbalance,
, computed in terms of the work associated
with the assignment statement of the loop body, and the corresponding
relative load imbalance, ![]() , for two different pairs of values
for N and BB,
, for two different pairs of values
for N and BB, ![]() , and
, and ![]() , are shown in
Table 2. It can be seen that MARS and KAP
exhibit high load imbalance, while the remaining
four schemes exhibit significantly smaller load imbalance;
CAN-3 exhibits, on average, the smallest value of load
imbalance.
, are shown in
Table 2. It can be seen that MARS and KAP
exhibit high load imbalance, while the remaining
four schemes exhibit significantly smaller load imbalance;
CAN-3 exhibits, on average, the smallest value of load
imbalance.
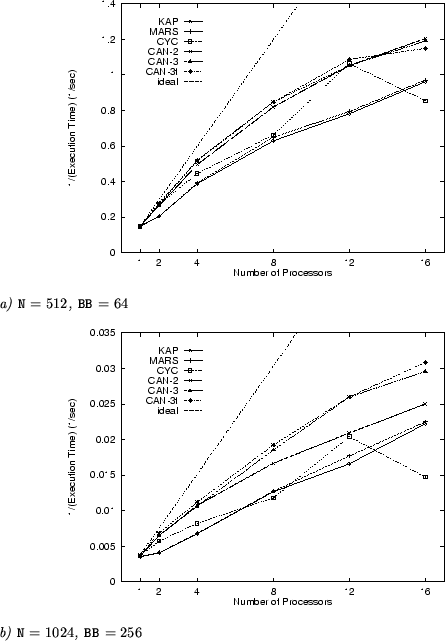
The partitioned programs were run on the KSR1, using the same two pairs of values for N and BB; their performance is depicted in Figure 6. In the first case, in Figure 6.a, KAP and MARS perform worst of all, except when running on 16 processors where CYC performs worst of all. CAN-3t performs best of all when using less than 12 processors; equally good results are achieved by CAN-3 and, to some extent, CAN-2. CYC exhibits a somewhat odd behaviour; it performs nearly best of all when running on 12 processors, but performs worst of all when running on 16 processors, and nearly worst when running on 8 processors. This is due to a significant number of cache misses when the number of processors is a power of 2.
Similar remarks can be made about the results depicted in Figure 6.b. CAN-3t performs best of all; CAN-3 exhibits a comparable performance, but CAN-2 performs significantly worse. KAP and MARS perform worst of all except when using 8 or 16 processors; in these cases, CYC, whose performance also suffers from a high number of cache misses as in Figure 6.a, performs worst of all.
Another interesting observation, in connection with the load imbalance computed in Table 2 and the actual performance depicted in Figure 6, is that, although CAN-3t nearly always exhibits a higher load imbalance than CAN-3 (except when the number of processors is 2), its actual performance is generally better than that of CAN-3 (except when running on more than 12 processors, where the difference in the anticipated load imbalance between the two partitioning schemes becomes comparatively higher); the performance gains of CAN-3t are due to the elimination of MIN and MAX functions from the loop bounds (apart from those necessary for partitioning the outermost, parallel loop).